
Rate Sheet Processing Is Costing Freight Forwarders More Than They Think
Most freight forwarders do not feel the cost of rate sheet processing the moment it happens, they feel it later.
The damage usually starts before anyone notices: a quote goes out two hours late, a surcharge buried in a footnote is missed, or sales uses last week’s rate while a valid amendment sits unread in an inbox. Sometimes the deal is lost. Sometimes it is won, only for the margin to disappear at invoice time. In a market shaped by rerouting, rate volatility, and constant cost pressure, weak pricing inputs quietly turn into commercial losses.
The cost hiding in the inbox
A forwarder can do a lot of things right and still lose money because the rate data underneath the quote was weak. That is why rate sheet processing deserves to be viewed as commercial infrastructure, not clerical work.
Stale rates create blind spots in the quote. Missed validity windows force teams to rework pricing or absorb the gap. And when local charges, surcharges, or exceptions are interpreted differently across offices, the dispute usually appears later, after the shipment has already moved.
The freight environment makes this worse, not better. In a market where carrier costs can shift materially within weeks due to congestion, rerouting, capacity changes, or surcharge updates, even a small delay between receiving a rate update and using it in a quote can create commercial risk.
The cost usually lands in three places.
Lost deals. A competitor with fresher rates and cleaner routing data answers faster and prices with more confidence. Your team may never learn that the deal was lost because the underlying cost input was outdated.
Margin leakage. The booking is won, but the real cost shows up later through missed surcharges, invalid sell assumptions, or late amendments.
Disputes and rework. Invoice mismatches, quote revisions, and manual firefighting consume the same pricing and operations talent you need for growth.
There is no universal public benchmark for how many carrier rate updates a mid-size forwarder processes per week. The right planning formula is company-specific: count active carriers, average updates per carrier, amendment frequency, local charge notices, and spot or exception messages by lane and mode. If you do not measure amendments and local charges separately, your current estimate is probably low.
The format reality is part of the problem.
Source format | What usually sits inside it | What commonly goes wrong |
|---|---|---|
PDF tariffs and contracts | Base rates, validity windows, surcharge notes, exceptions | Table extraction errors, hidden footnotes, superseded pages |
Excel or XLSX rate cards | Multi-sheet lane tables, local charges, formulas, tabs by trade | Column drift, wrong tab selection, broken formulas, missed amendments |
Email body text | Ad hoc changes, validity extensions, urgent spot offers, caveats | No clean version history, incomplete capture, hidden exceptions |
Portal pages and downloads | Carrier-specific schedule or route-linked pricing data | Manual copy-paste, brittle workflows, missing audit history |
EDI messages | Structured transactional data where supported | Partial coverage, mapping mismatches, partner dependency |
API JSON feeds | Structured schedules, availability, event data, sometimes pricing | Great when supported, but uneven across carriers and use cases |
The mixed-channel problem is real. Booking data still moves through a mix of email, carrier portals, EDI, spreadsheets, and manual follow-ups. Schedule updates, shipment milestones, and rate-related information are not always shared in the same structure or at the same speed. Digital standards and carrier APIs are improving the picture, but they will not remove years of PDFs, spreadsheets, email amendments, and portal downloads overnight.
Why the workflow breaks
Rate sheet processing breaks because every rate carries context. It is not enough to extract a number from a PDF or spreadsheet. The system also has to understand where that number applies, when it is valid, what charges sit around it, which exceptions change it, and whether it is safe to use in a quote.
That is where many workflows fail. They capture the rate, but lose the meaning behind it.
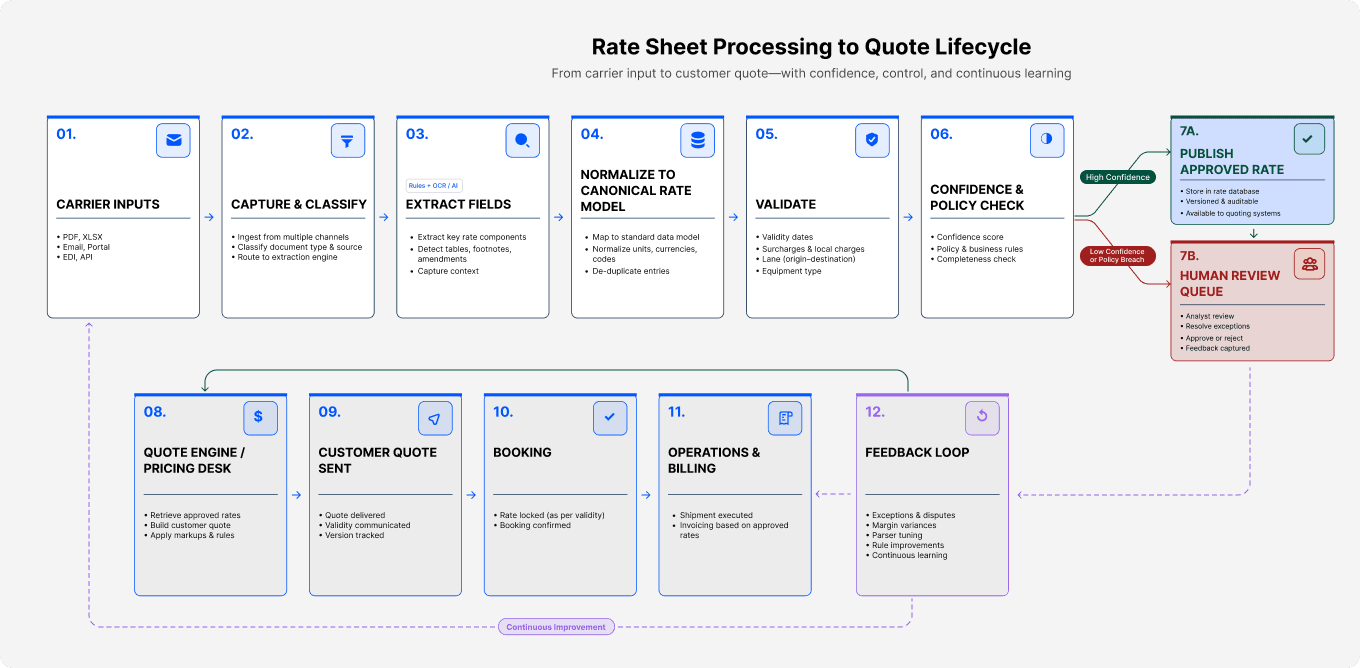
That flow is where small assumptions become expensive. A rate entered from the wrong version, a surcharge missed during extraction, or a validity date interpreted incorrectly can move all the way into the customer quote before anyone catches it.
The hard part is not just reading the file. It is keeping the context intact. Carrier data often moves across emails, portals, spreadsheets, PDFs, and manual updates. Each handoff creates room for rekeying errors, missed footnotes, inconsistent formats, and delayed approvals.
Table-heavy PDFs make this worse. So do scanned documents, merged cells, hidden notes, amended sheets, and poor formatting. One extraction error can become a pricing error. One pricing error can become a margin issue. One margin issue can become an invoice dispute after the shipment has already moved.
Failure modes and mitigation actions
Failure mode | Where it appears | Typical impact | Mitigation action |
|---|---|---|---|
Updated rate not ingested fast enough | Inbox, portal, shared folder | Quote sent from stale data, lost deal | Automate intake and timestamp receipt, set publish SLA |
Wrong version selected | Shared drives, email threads | Expired or superseded rate used | Version control with supersession rules and source fingerprint |
OCR or extraction misreads a field | PDF or scan parsing | Wrong currency, lane, charge, or validity | Confidence scoring, field-level validation, human review queue |
Surcharge logic omitted | Quote build | Margin leakage, post-booking correction | Separate surcharge model with effective dates and mandatory checks |
Port or lane normalization mismatch | Data mapping | Invalid comparison across carriers | Canonical port and lane dictionary with alias resolution |
Duplicate or overlapping rates | Repository | Inconsistent quote result by user or office | Priority hierarchy, deduplication rules, supersession logic |
Manual override without audit trail | Quote approval | Unexplained margin variance, dispute exposure | Reason codes, named approver, immutable history |
Quote outlives source validity | Post-send | Reprice, customer friction, leakage | Quote expiry tied to source validity and auto-refresh alerts |
Rekey into TMS or ERP | Hand-off to operations | Downstream mismatch, invoice dispute | API-based handoff or synchronized canonical rate object |
These failure modes are a practical synthesis of the current industry’s multi-channel data reality and the known behavior of document-extraction systems under layout variation.
They are also why rate sheet processing cannot be treated as a pure OCR task. It is workflow design, control design, and data governance as much as it is extraction.
Which solutions help and where they fail
There is no single fix because rate inputs do not arrive in a single shape. One carrier sends a clean Excel file. Another sends a scanned PDF. A third updates a surcharge through a portal note. An amendment may arrive as a one-line email. Each one needs a different processing path.
Works well when the carrier format is stable. Fixed columns, repeat templates, known tabs, and predictable surcharge fields can be processed quickly. The weakness shows up when the carrier changes the layout, adds a new charge label, merges cells, moves notes into footers, or sends an amendment outside the usual format. Rules are fast, but brittle.
Useful for messy PDFs, semi-structured spreadsheets, and first-pass field extraction. It can identify tables, pull rate fields, detect notes, and reduce manual entry. But AI alone does not know whether a rate is commercially safe to quote. It still needs validation around validity dates, surcharge logic, currency, equipment type, amendment status, and exceptions. Extraction is not the same as approval.
Strong where structured partner connectivity already exists. EDI can reduce manual exchange and improve consistency for high-volume transactions. But coverage is uneven, onboarding takes work, and not every carrier update, local charge, spot rate, or amendment flows cleanly through EDI. It helps the structured part of the problem, not the messy long tail.
Clean and fast when available. APIs are useful for structured data such as schedules, status updates, availability, and certain pricing workflows. The limitation is coverage. Not every carrier exposes the same data, not every API follows the same structure, and many real-world rate updates still arrive through PDFs, spreadsheets, emails, and portals. APIs improve the future state, but they do not erase the current document problem.
Good for absorbing volume. A BPO team can process backlogs, handle repetitive entry, and reduce pressure on internal pricing teams. But it does not remove the complexity. A confusing surcharge note is still confusing offshore. A 200-page PDF still needs interpretation. A wrong rate loaded by a third-party team causes the same margin damage as a wrong rate loaded internally.
Useful once the rate data is already clean. A TMS can store rates, support quoting, and connect pricing to operations. But many TMS modules are not built to solve messy rate ingestion at the source. If the carrier data still has to be cleaned, interpreted, and normalized before upload, the core burden remains with the pricing team.
The strongest approach combines multiple methods. Use APIs or EDI where the data is already structured. Use rules where carrier templates repeat. Use AI where the format is messy but readable. Send low-confidence fields, unclear amendments, and margin-sensitive exceptions to human review.
That is the practical answer. Not full manual. Not AI alone. Not a single fixed workflow. A forwarder that forces every rate sheet through one method eventually rebuilds a manual fallback. The better model is a system that chooses the right path based on the rate sheet itself.
What good looks like in production
Good production design treats the carrier file as the input, not the source of truth.
The real source of truth should be a normalized, governed rate record that is clean enough to quote from, traceable enough to defend, and controlled enough to prevent obvious pricing mistakes. That record needs more than a base rate. It should carry the
- Mode
- Carrier
- Contract type
- Origin and Destination
- Service
- Equipment type or weight break
- Base rate
- Surcharges
- Currency
- Validity dates
- Local charges
- Source document
- Amendment status
- Approval state, and
- Any business-rule flags.
Without that structure, automation becomes fragile. The system may extract a number correctly but still miss what matters commercially: when the rate applies, which customer can use it, which charges sit around it, and whether a newer amendment has already replaced it.
Before any rate reaches quoting, it should pass a validation layer. That means checking effective and expiry dates, currency, units, lane mapping, equipment type, duplicate coverage, surcharge completeness, local-charge dependencies, named-account rules, and margin floors. This is where many automation projects fall short. They automate extraction, but not quote readiness.
The right workflow should also avoid sending everything back to humans. Human review should be reserved for the cases that actually need judgment: new carrier formats, low-confidence fields, unclear amendments, conflicting validity windows, missing surcharges, margin-sensitive exceptions, or anything that could create customer-facing risk.
Every approved rate should also leave a clear audit trail. The team should be able to see where the rate came from, when it was imported, what changed, who approved or overrode it, and which quotes or bookings used it. If a dispute appears later, pricing, operations, and finance should be able to reconstruct the exact rate logic behind the quote.
The final test is integration. A governed rate is only useful if it flows into the systems where work actually happens. Rate data should move from intake into quoting, then into the TMS, ERP, billing, CRM, and reporting layers without repeated rekeying.
That is the difference between a rate repository and a rate-processing system.
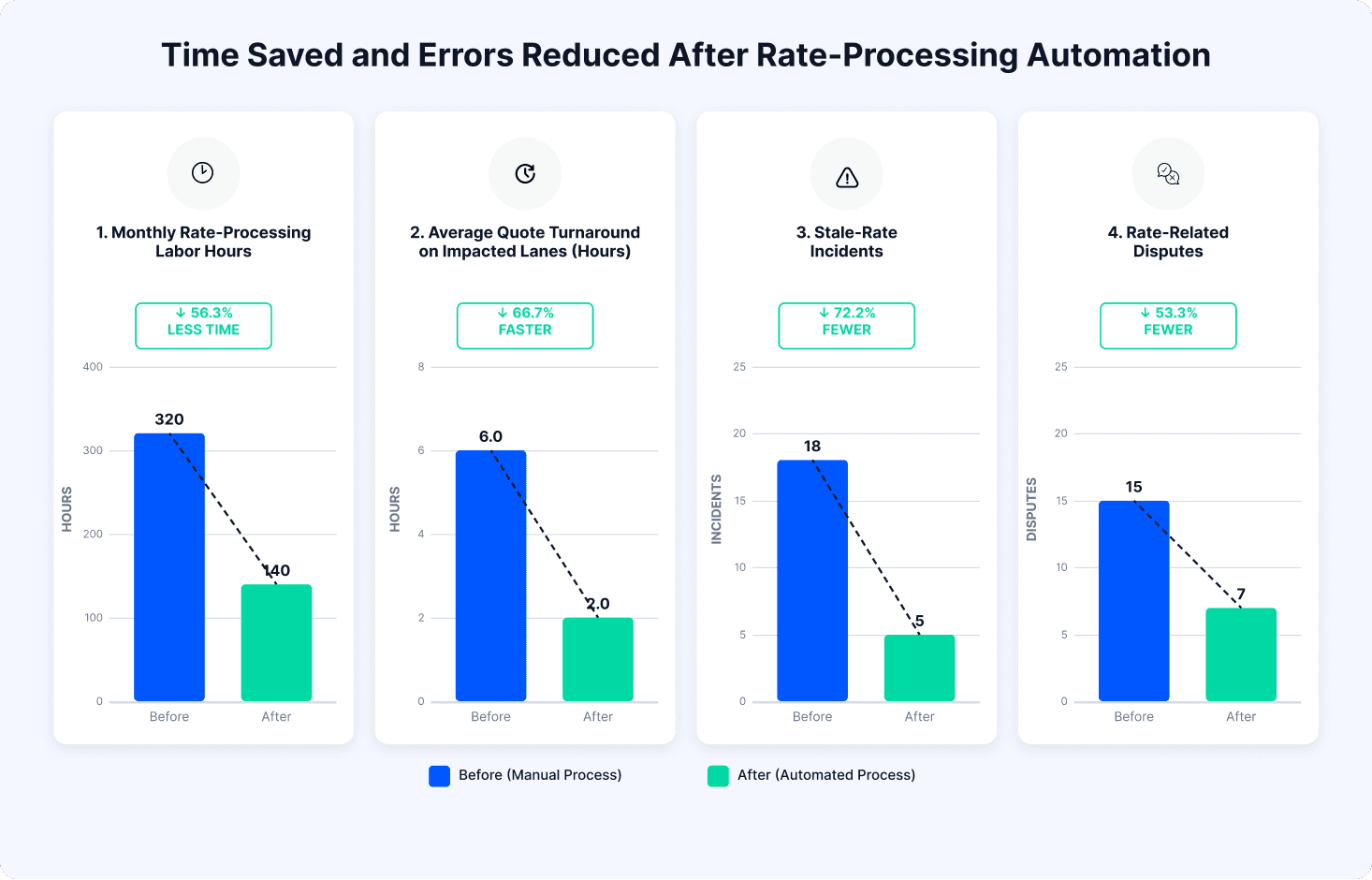
How to implement and prove ROI
A big-bang rollout sounds decisive. In practice, it usually creates noise before it creates value.
Start with one controlled slice of the rate operation. It should be small enough to measure clearly, but large enough to prove commercial impact.
Start with a focused pilot
- One region
- One mode
- Five to ten priority carriers
Lane families with high quote volume or visible margin pain
A clean, repeatable carrier template
A messy but common PDF or spreadsheet
An amendment-heavy example with unclear changes
If the pilot only proves speed on clean templates, it does not prove much. The real test is whether the workflow can handle the documents that slow your team down today.
Automation will only work if teams trust the process. Pricing teams will resist a black box. Sales teams will bypass the system if exceptions take too long. Operations will lose confidence if the quote logic cannot be explained later.
The rollout should make ownership, approval rules, confidence levels, risk flags, and override reasons visible from the start. The goal is not to remove control from the team but to give them cleaner data, clearer review paths, and fewer manual checks. After automation, the team should feel more in control, not less.
Before investing in a new workflow, build a baseline. The numbers below are illustrative, but the structure is useful. Replace each assumed value with your own operational data.
ROI item | Example value | Notes |
|---|---|---|
Rate files and amendments processed per month | 1,500 | Assumed baseline |
Manual handling time per file | 16 minutes | Current process |
Assisted handling time per file | 6 minutes | After automation |
Loaded labor cost | $40 per hour | Fully loaded cost |
Quote-linked shipments per month | 320 | Shipments tied to quoted rates |
Share of shipments with avoidable leakage today | 20% | Assumed leakage exposure |
Average avoidable leakage per impacted shipment | $130 | Assumed margin impact |
Rate-related disputes per month | 15 | Current dispute volume |
Admin cost per dispute | $75 | Internal handling cost |
Dispute reduction after rollout | 50% | Expected improvement |
Extra quotes handled per month because turnaround improves | 80 | Added quoting capacity |
Conversion on extra quotes | 15% | Expected win rate |
Average gross profit per won shipment | $180 | Assumed gross profit |
Annual platform plus implementation cost | $160,000 | Estimated annual cost |
Annual labor savings | $120,000 | 1,500 × 10 minutes saved × 12 ÷ 60 × $40 |
Annual recovered margin | $99,840 | 320 × 20% × $130 × 12 |
Annual dispute savings | $6,750 | 15 × $75 × 50% × 12 |
Annual gain from extra won shipments | $25,920 | 80 × 15% × $180 × 12 |
Total annual benefit | $252,510 | Sum of benefit rows |
Net annual benefit | $92,510 | Total benefit minus annual cost |
Simple ROI | 57.8% | Net benefit ÷ annual cost |
Estimated payback period | 7.6 months | Annual cost ÷ monthly benefit |
This model is intentionally conservative. It does not include softer gains such as faster onboarding for new pricing analysts, less quote rework, better consistency across offices, cleaner audit trails, or fewer customer escalations.
Those gains still matter. They just tend to show up outside the spreadsheet.
Track the right KPIs from week one
If you do not measure the workflow, you may end up buying a feature instead of fixing a process.
Keep the KPI set short, practical, and difficult to game:
Publish latency: Time from rate update receipt to approved availability in quoting
First-pass extraction accuracy: Measured by carrier and document type
Exception rate: Percentage of files or fields routed for review
Top exception reasons: Missing surcharge, unclear amendment, expired validity, wrong format, duplicate rate
Stale-rate incidents: Number of quotes exposed to outdated or superseded rates
Quote turnaround time: Especially on the pilot lanes
Quote-to-book conversion: Whether faster, cleaner pricing helps win more business
Gross margin variance: Difference between quoted margin and invoiced result
Rate-related disputes: Count, value, and resolution time
User bypass rate: Quotes created outside the governed workflow
The most important metric is not extraction accuracy alone. It is whether approved rates lead to faster quotes, cleaner margins, and fewer disputes.
Be honest about the limitations
No serious forwarder should expect every rate sheet to become touchless. Not every input can be processed automatically. Portals can be difficult to capture consistently, carrier documents may require business context to interpret correctly, and complex layouts with footnotes, amendments, or poor formatting often still benefit from human review. Even strong automation needs monitoring, review rules, and ongoing improvement.
The goal is not to automate everything but to automate what is repeatable, flag what is risky, and make every approved rate traceable from source document to quote.
Focus on the moves that create measurable progress first:
Define the canonical rate model before evaluating tools
Measure your current baseline before changing the process
Pilot on the carriers and lanes that create the most quote pain
Include messy documents, not just clean templates
Set publish rules for high-confidence cases
Set review rules for high-risk cases
Make every approval and override traceable
Connect approved rates into quoting, operations, and billing
Measure margin variance, not just extraction accuracy
Pilot checklist
Before launch, prepare the pilot like an operating project, not a software demo.
Gather 60 to 100 recent rate files, including clean, messy, and amendment-heavy examples
Map current intake channels: email, shared folders, portals, EDI, APIs
Define the fields required for a quote-ready rate
Agree on exception rules and approver roles before the pilot starts
Pick lanes with meaningful quote volume or visible margin pain
Baseline current turnaround time, dispute rate, and quoted-versus-invoiced margin data
Review results by carrier, document family, and exception reason
Separate speed gains from commercial gains
Decide what can be auto-published, what needs review, and what should never reach quoting without approval
A good pilot should answer one simple question:
Can this workflow turn messy carrier inputs into approved, traceable, quote-ready rates faster than the current process, without adding new pricing risk?
FAQs
Rate sheet processing is the work of turning carrier pricing inputs into quote-ready data. That includes capturing source files or messages, extracting the relevant fields, normalizing them into a consistent structure, validating them against policy and rate logic, and making the approved result available to the quote desk and downstream systems.
Because the rate drives the quote, and the quote drives win rate, margin, and downstream invoice accuracy. When the pricing input is late, stale, or wrong, the damage shows up commercially as lost deals, underquoted shipments, and disputes. DCSA’s standards work on adjacent shipping workflows makes this broader pattern clear: non-standardized, manual, multi-channel data flows create delay, rekeying, and financial loss.
Yes, often. Not always. AI extraction is useful, especially on semi-structured PDFs and variable spreadsheets, but document-processing research still shows that image quality, layout variation, table structure, and field ambiguity can affect outcomes. That is why the best production setups combine AI with validation rules, confidence thresholds, and human review for risky exceptions.
They solve the cleanest part of the problem. They do not solve the whole thing. Industry standards and carrier APIs are increasingly important, and DCSA’s standards plus carrier API portals point to the right long-term direction. But freight forwarders still live in a mixed environment where email, web portals, spreadsheets, PDFs, EDI, and APIs coexist.
Because outsourcing changes where the work is done, not whether the source data is ambiguous. A BPO can reduce backlog and absorb volume, but it still has to interpret the same PDFs, amendments, footnotes, and exceptions. If the source is unclear, the core risk remains.
At minimum: validity dates, lane or location normalization, currency and unit consistency, surcharge completeness, duplicate or overlapping rate coverage, customer applicability, and approval rules such as margin floors or exception policies.
Start with publish latency, first-pass extraction accuracy, exception rate, stale-rate incidents, quote turnaround time, quote-to-book conversion on pilot lanes, and gross margin variance between quoted and invoiced results.
Start with a focused pilot. One region, one mode, five to ten priority carriers, and the lane families where slow quoting or margin leakage hurts most. Build the canonical rate model first, define exception handling before launch, and judge success on business outcomes, not demo speed alone.
Not full touchless automation on every document.
The right end state is a governed workflow where low-risk updates move quickly, high-risk exceptions get reviewed by the right people, every change is traceable, and approved rates flow cleanly into quoting, operations, and billing. That is what turns rate sheet processing from a firefight into a commercial asset.